
Virtual Try-On is a promising research area with broad applications in e-commerce and everyday life, enabling users to visualize garments on themselves or others before purchase. Most existing methods depend on predefined or user-specified masks to guide garment placement, but their performance is highly sensitive to mask quality, often causing misalignment or artifacts, and introduces redundant steps for users. To overcome these limitations, we propose a mask-free virtual try-on framework that requires only minimal modifications to the underlying architecture while remaining compatible with common diffusion-based pipelines. To address the increased ambiguity in the absence of masks, we integrate an attention-based guidance mechanism that explicitly directs the model to focus on the target garment region and improves correspondence between the garment and the person. Additionally, we incorporate instruction prompts, allowing users to flexibly control garment categories and wearing styles, addressing the underutilization of prompts in prior work and improving interaction flexibility. Both qualitative and quantitative evaluations across multiple datasets demonstrate that our approach consistently outperforms existing methods, producing more accurate, robust, and user-friendly try-on results.
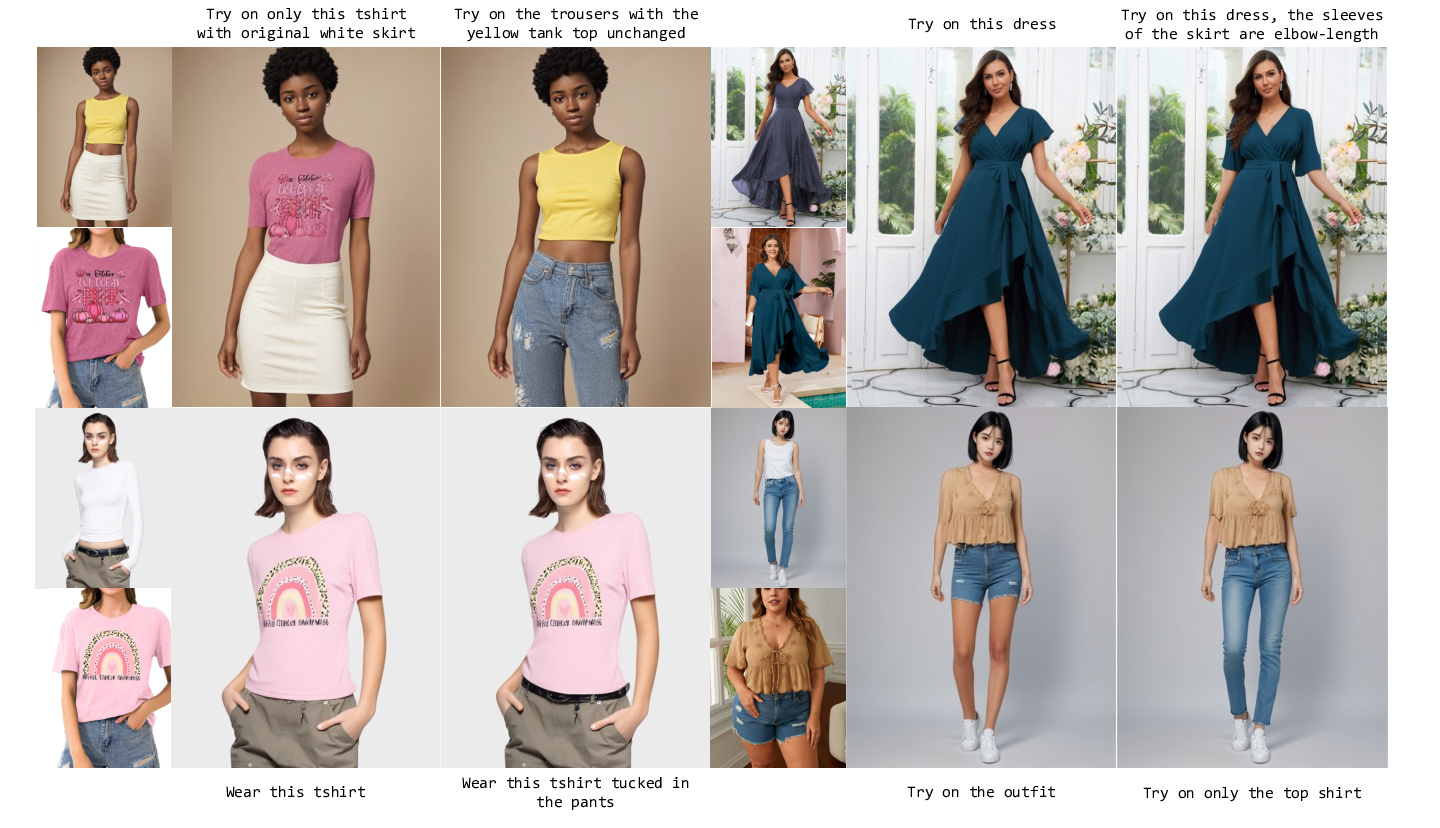
Our method can follow text instructions to guide the virtual try-on process, enabling flexible control over the style and appearance of clothing items. By leveraging natural language descriptions, users can specify desired clothing attributes such as color, pattern, texture, and style modifications without requiring explicit mask annotations or manual editing.
The text instruction mechanism allows for intuitive interaction with the virtual try-on system, where users can describe their desired clothing modifications in natural language. Our approach processes these text instructions and translates them into style-aware features that guide the try-on process, resulting in photorealistic outputs that match the user's textual descriptions. This capability significantly enhances the flexibility and user-friendliness of virtual try-on applications.
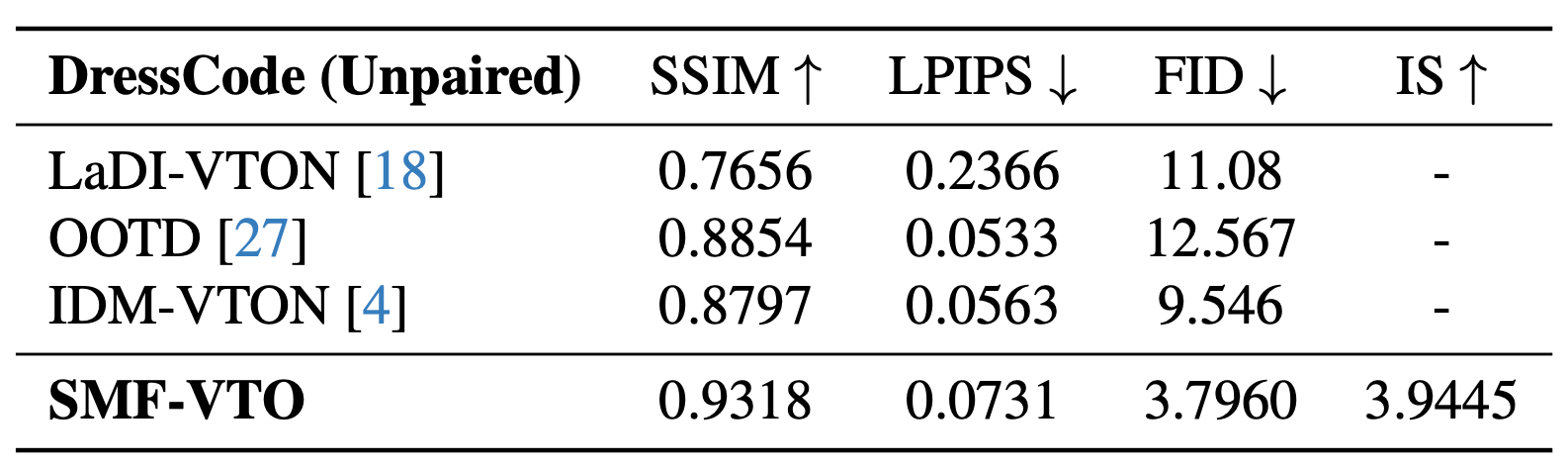
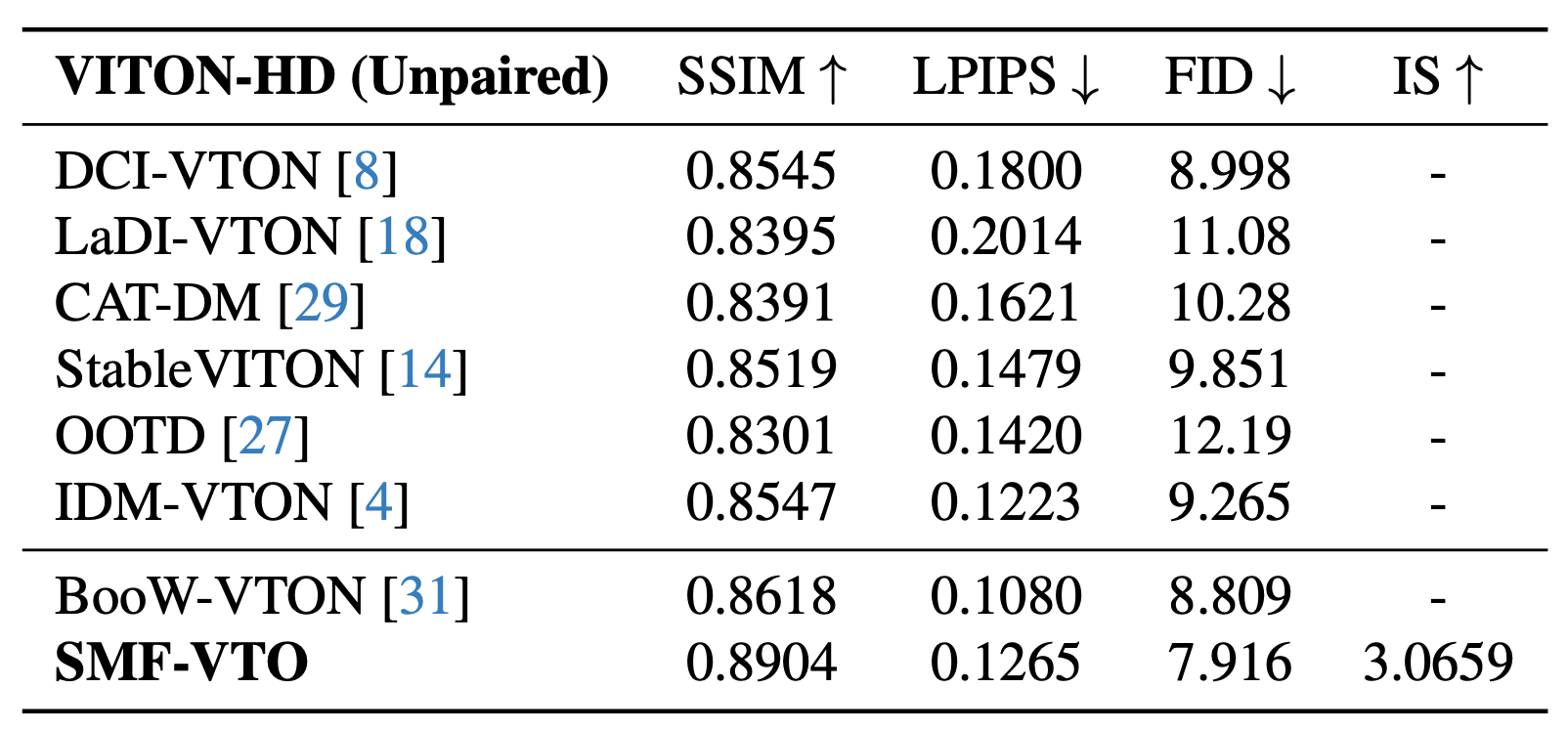
We evaluate our method on standard benchmarks and compare with state-of-the-art methods. The quantitative results demonstrate the effectiveness of our approach.
We conduct comprehensive ablation studies to analyze the contribution of different components in our method, demonstrating the effectiveness of each design choice. Our ablation experiments systematically evaluate the impact of key components including the style instruction mechanism, mask-free architecture, and feature extraction modules.
The ablation results reveal the importance of each component in achieving high-quality virtual try-on results. We analyze the contribution of style-aware features, text instruction processing, and the mask-free design philosophy. The experiments demonstrate that removing any of these components leads to noticeable degradation in performance, validating the necessity of our integrated approach.
